Blog
L’idea di Git è di salvare varie versioni apportate ai file in un repository.
Le modifiche apportate si salvano sotto forma di commit. Ogni commit contiene le differenze tra i file modificati e la loro precedente versione che si vogliono salvare. Idealmente, ogni commit dovrebbe rispettare il principio di singola responsabilità: dovrebbe cioè riguardare una sola funzionalità o caratteristica del software. Ogni commit porta con sé un messaggio che descrive brevemente cosa è stato modificato, un timestamp non modificabile e un hash che consente di identificarlo univocamente.
Il repository conterrà quindi una serie di commit ordinati temporalmente. I commit possono essere raggruppati in “branch” (rami), che si usano per separare strade differenti che il software può prendere. Un commit può appartenere a più branch. I branch possono fondersi tra di loro tramite “merge”. Se il merge genera dei conflitti, ad esempio se entrambi i branch modificano una certa parte di un file, viene lasciata all’utente la scelta di cosa tenere e cosa togliere.
Puoi immaginare Git come se ci fossero diverse aree di memoria per lo stesso codice sorgente. Le aree di memoria possono rappresentare versioni diverse dello stesso codice oppure la stessa identica versione. Le aree di memoria sono le seguenti:
- La working directory è la directory di lavoro dove si trovano i file che stai modificando. Al suo interno vi sarà una directory “.git” che contiene tutti i dati sul repository.
- La staging area è l’insieme dei file modificati e tracciati dal repository (se crei un nuovo file, non viene automaticamente tracciato).
- Il repository è la vera e propria memoria delle versioni, esiste in locale e ha una o più copie remote.
Questa figura schematizza i principali comandi di Git e come questi interagiscono con le aree di memoria. Le frecce dell’immagine indicano i comandi da usare per aggiungere/togliere dal tracciamento, per salvare le modifiche (commit) e per aggiornare il codice con modifiche avvenute sul repository remoto (ad esempio modifiche effettuate da altri utenti).
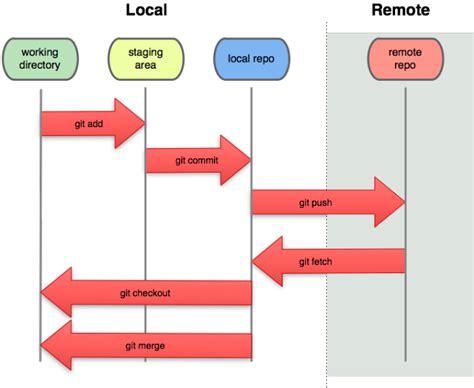
In tutti i software grafici (gitg, gitahead, ecc.) trovi sempre la possibilità di effettuare queste operazioni di base. Le cose si complicano quando si iniziano a usare branch differenti, ma per ora non ci interessa. La cosa importante da capire è che Git è effettivamente pensato per salvare la storia dello sviluppo; la storia non si può cancellare e quindi non si può tornare indietro. Esistono tool appositi, ma l’idea di usare Git è accettare che ogni modifica apportata non deve mai essere cancellata, nemmeno se introduce un errore; è invece più utile ricordarla per capire i motivi per cui il software si è sviluppato in un certo modo.